Dissecting the Disruptor: Wiring up the dependencies
So now I’ve covered the ring buffer itself, reading from it and writing to it.
Logically the next thing to do is to wire everything up together.
I talked about multiple producers - they have the producer barrier to keep them in order and under control. I’ve talked about consumers in a simple situation. Multiple consumers can get a little more involved. We’ve done some clever stuff to allow the consumers to be dependent on each other and the ring buffer. Like a lot of applications, we have a pipeline of things that need to happen before we can actually get on with the business logic - for example, we need to make sure the messages have been journalled to disk before we can do anything.
The Disruptor paper and the performance tests cover some basic configurations that you might want. I’m going to go over the most interesting one, mostly because I needed the practice with the graphics tablet.
Diamond configuration
DiamondPath1P3CPerfTest illustrates a configuration which is not too uncommon - a single producer with three consumers. The tricky point being that the third consumer is dependent upon the previous two consumers to finish before it can do anything.

Consumer three might be your business logic, consumer one could be backing up the data received, and consumer two may be preparing the data or something.
Diamond configuration using queues
In a SEDA-style architecture, each stage will be separated by a queue:

(Why does queue have to have so many “e"s? It’s the letter I have the most trouble with in these drawings).
You might get an inkling of the problem here: for a message to get from P1 to C3 it has to travel through four whole queues, each queue taking its cost in terms of putting the message on the queue and taking it off again.
Diamond configuration using the Disruptor
In the Disruptor world, it’s all managed on a single ring buffer:
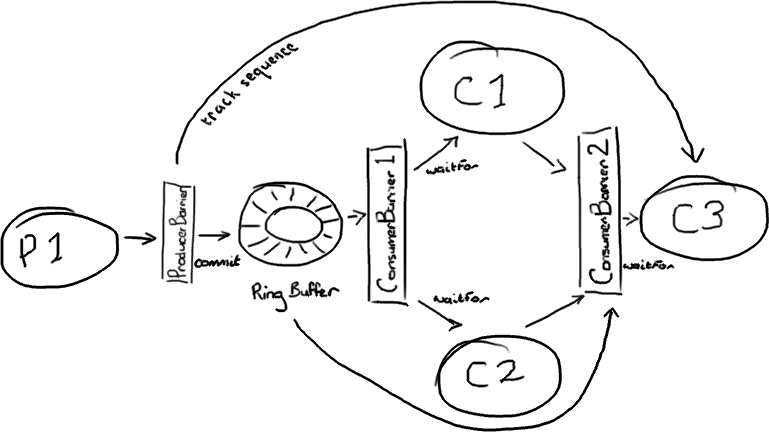
It does look more complicated. But the ring buffer remains the single point of contact between all the players, and the interactions are all based on the barriers checking the sequence numbers of the things it’s dependent upon.
The producer side is fairly simple, it’s the single producer model described in my last post. Interestingly, the producer barrier doesn’t have to care about all the consumers. It only cares about consumer three, because if consumer three has finished with an item in the ring buffer the other two will already have processed it. So if C3 has moved on, that slot in the ring buffer is available.
To manage the dependencies between the consumers you need two consumer barriers. The first just talks to the ring buffer and consumers one and two ask it for the next available item. The second consumer barrier knows about consumers one and two, and it will return the lowest sequence number processed by both consumers.
How consumer dependencies work in the Disruptor
Hmm. I can see I’m going to need an example.
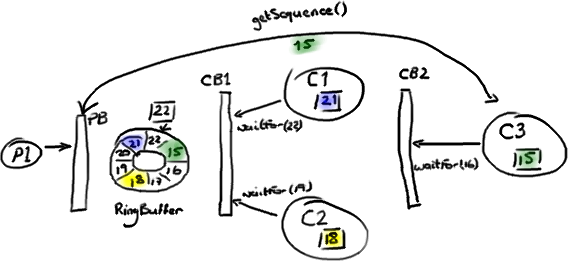
We’re joining the party halfway through the story: the producer has filled the ring buffer up to sequence number 22; consumer one has read and processed everything up to 21; consumer two has processed everything up to sequence 18; consumer three, which is dependent upon the other consumers, has only made it as far as 15.
The producer can’t write anything more to the ring buffer because sequence 15 is taking up the slot where we’d want to put sequence 23.

(I’m sorry, I really did try to find an alternative to red and green, but everything else was just as ambiguous).
The first consumer barrier lets consumers one and two know they can grab anything up to sequence 22, the highest sequence number in the ring buffer. The second consumer barrier checks the ring buffer sequence, but it also checks the sequences on the other two consumers and returns the lowest value. So consumer three is told it can get anything up to sequence 18 from the ring buffer.
Note that the consumers are still reading the entries directly from the ring buffer - consumers one and two are not taking the entries off the ring buffer and then passing them on to consumer three. Instead, the second consumer barrier is letting consumer three know which entry in the ring buffer it’s safe to process.
This raises a question - if everything comes directly off the ring buffer, how is consumer three going to find out about anything the first two consumers have done? If all consumer three cares about is that the earlier consumers have done their job (e.g. replicating the data to somewhere else) then everything’s fine - when consumer three is told the job is done, it’s happy. If, however, consumer three needs the results of an earlier consumer’s processing, where does it get that from?
Modifying entries
The secret is to write them to the ring buffer Entry itself. This way, when consumer three grabs the entry off the ring buffer, it will have been populated with all the information consumer three needs to do the job. The really important part of this is that for each field on the Entryonly one consumer is allowed to write to it. This prevents any write-contention which will slow the whole thing down.

You can see this in DiamondPath1P3CPerfTest - FizzBuzzEntry has two fields as well as the value: fizz and buzz. If the consumer is a Fizz consumer, it writes to fizz. If it’s a Buzz consumer, it writes to buzz. The third consumer, FizzBuzz, will read both of these fields but not write to either, since reading is fine and won’t cause contention.
Some actual Java code
All this looks more complicated than the queue implementation. And yes, it does involve a bit more coordination. But this is hidden from the consumers and producers, they just talk to the barriers. The trick is in the configuration. The diamond graph in the example above would be created using something like the following:
ConsumerBarrier consumerBarrier1 = ringBuffer.createConsumerBarrier();
BatchConsumer consumer1 = new BatchConsumer(consumerBarrier1, handler1);
BatchConsumer consumer2 = new BatchConsumer(consumerBarrier1, handler2);
ConsumerBarrier consumerBarrier2 = ringBuffer.createConsumerBarrier(consumer1, consumer2);
BatchConsumer consumer3 = new BatchConsumer(consumerBarrier2, handler3);
ProducerBarrier producerBarrier = ringBuffer.createProducerBarrier(consumer3);
In summary
So there you have it - how to wire up the Disruptor with multiple consumers that are dependent on each other. The key points:
- Use multiple consumer barriers to manage dependencies between consumers.
- Have the producer barrier watch the last consumer in the graph.
- Allow only one consumer to write to an individual field in an
Entry.
EDIT: Adrian has written a nice DSL to make wiring up the Disruptor much easier.
EDIT 2: Note that version 2.0 of the Disruptor uses different names to the ones in this article. Please see my summary of the changes if you are confused about class names. Also Adrian’s DSL is now part of the main Disruptor code base.